Temporal graphs for recommender systems
a data science project to use temporal graphs to recommend music
Motivation and goal
“Nearly 616.2 million people listen to their favorite artists or discover new ones via online streaming platforms”[^statista]. Hence, streaming platforms seek to increase enhance the user experience by offering personalized music recommendations, moreover, users value personalization as a top feature [^spotify]. At the same time, music streaming services are able to track individual preferences meticulously, thus, a growing volume of data on multiple user’s musical preferences is available. In response, we aimed to develop a recommendation model that predicts the genres a user is expected to like.
Dataset
We worked with tgbn-genre dataset, a temporal evolving graph from Temporal Graph Benchmark (TGB) 1. The grapgh ( tgbn-genre_edgelist) consists of 992 users and 513 music genre represented as nodes and weighted edges that indicates a user listens to a music genre at a given time. The temporal graph evolves over the span of 4 years and 4 months approximately. This dataset was generated by merging the LastFM dataset2 and million songs3 dataset with some preprocessing. The LastFM dataset has data on 992 users listening to songs on the last.fm website along with the timestamps of the songs play. The million songs dataset has data on songs and their respective genre/tags along with the weights assigned to each genre/tag.
The dataset tgbn-genre_edgelist posed a challenge since the description given by the creators of the dataset did not match it. Additionally, it has anomalies and multiple duplicates. Hoewever, it was then processed into tgbn-genre_node_labels a dynamical frequency interaction matrix where the interaction of each user and each genre is normalized over the span of a week. We train our models on this second dataset. Nevertheless, we explore the first dataset to comprehend the second one.

“The Million Song Dataset”. In Proceedings of the 12th International Society for Music Information Retrieval Conference (ISMIR 2011), 2011. http://millionsongdataset.com/
Exploratory Data Analysis
As previously mentioned, the tgbn-genre dataset posed a challenge. In raw-data-notebook we showcase the duplicates and anomalies on the dataset.
Later, we processed the data into tgbn-genre_node_labels (see eda-data-notebook ). This proccess ‘discretize’ our data. We partition the total time range of the dataset into more-or-less 24-hour periods and combine all records for a given user and genre in a given 24-hour period into a single record for that day, by summing the corresponding edge weights. The sum of the edge weights over a 24-hour period represents a user’s genre interactions for that day.
Then, for each user-genre pair, the discretized edge weight over each seven-day period are combined into a single number between 0 and 1. The number, called a ‘label_node’, reflects a user’s proclivity towards a certain genre over a given week, relative to all other genres. If a user doesn’t listen to any songs belonging to a certain genre during the week, the weight corresponding to that genre is 0. If a user listens exclusively to songs that are 100% a certain genre during the week, the weight corresponding to that genre is 1. The label_nodes are normalized so that they sum to 1.
In the process, we performed a comparison including and non including the duplicate records. After the process we found the distribution of the error is largely centred around 0 as desired.
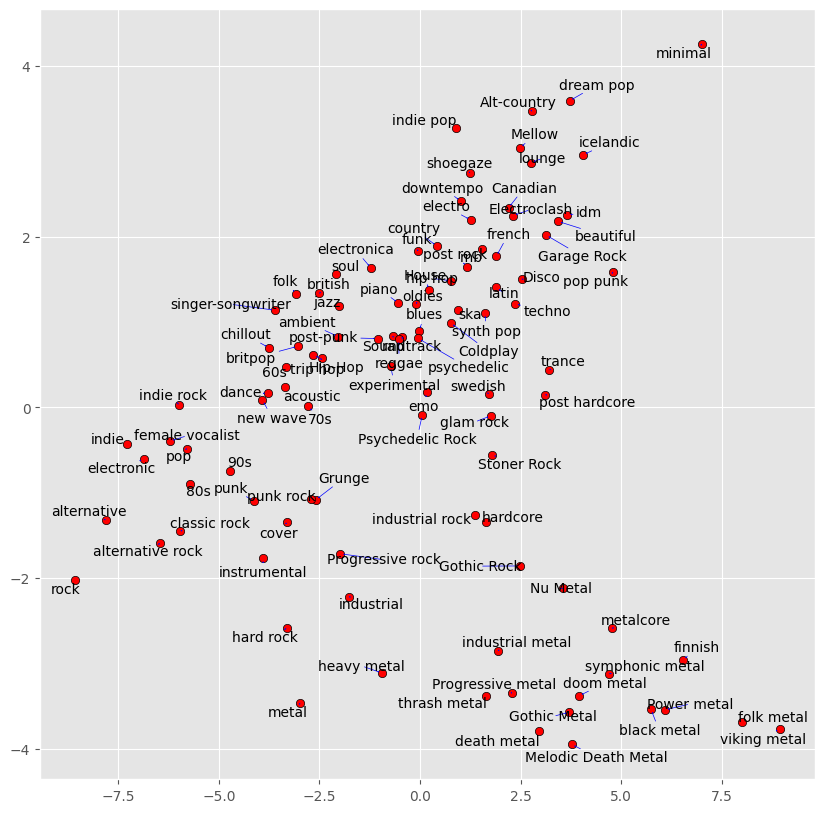
On the other hand, we evaluate some features on our data in the feature_generation directory finding a similarity graph of music genres.
Modelling Approach
Train-test-split: We split chronologically into the train, validation and test set with 70\%, 15\% and 15\% of the edges respectively.
Models: We experimented with several time series models. For the baseline model we chose the latest node label, i.e., for each user and genre in the test dataset, we look at the latest weight of that user for that genre in the training set and use that as the prediction. We looked at the time signal of the user genre weights for many users and did not find any seasonality or trend. Moreover, it was not feasible to detect seasonality or trend for all 992 users with a scalable algorithm.
Then we tried rolling average and did hyperparameter tuning with the window parameter. Finally we tried exponential smoothing with hyperparameter tuning on the smoothing parameter.
Key performance indicator: We use the normalized discounted cumulative gain with 10 items (NDCG@10)4. It is the sum of the relevance of the item divided by the log basis two of the rank of the item plus one. So this is a holistic metric that accounts for both the relevance of the item and the rank of the prediction. To get the normalized version of the discounted cumulative gain, the discounted cumulative gain is divided by the maximum possible score.
Results
| Model | NDCG @10 (Validation) +- 0.0001 | NDCG @10 (Test) +-0.0001 |
|---|---|---|
| Latest node label (Baseline) | 0.18068 | 0.1575 |
| Mean node label | 0.2310 | 0.2034 |
| Median node label | 0.2140 | 0.1888 |
| Rolling average (Window=7) | 0.2242 | 0.1951 |
| Rolling average (Window=14) | 0.2333 | 0.2008 |
| Rolling average (Window=21) | 0.2345 | 0.2014 |
| Exponential Smoothing ($\alpha=0.8$) | 0.1941 | 0.1662 |
| Exponential Smoothing ($\alpha=0.4$) | 0.1827 | 0.1619 |
Conclusions and Future Directions
We want to exploit the graph structure of our data to train graph neural networks and learn the interaction of users and music genres. Also, train classical and deep learning multivariate time series models to analyze the music genre preferences of one user. Ultimately, offer streaming services a recommendation system that can create a great and unique experience for each user.
-
Huang, S., et al.”Temporal graph benchmark for machine learning on temporal graphs” Advances in Neural Information Processing Systems , 2023. Preprint: arXiv:2307.01026, 2023. ↩
-
Celma O. “Music Recommendation and Discovery in the Long Tail”. Springer. Ch. 3. 2010. http://ocelma.net/MusicRecommendationDataset/lastfm-1K.html. ↩
-
Bertin-Mahieux T. , Ellis D., Whitman B., and Lamere P. . ↩
-
Evidently AI Team. “Normalized Discounted Cumulative Gain (NDCG) explained” https://www.evidentlyai.com/ranking-metrics/ndcg-metric#:~:text=Normalized%20Discounted%20Cumulative%20Gain%20(NDCG)%20is%20a%20ranking%20quality%20metric,the%20top%20of%20the%20list. Accessed Jun 1, 2024. ↩